近期在外部刷到一个帖子,大意是 gpt-3.5 模型套上 harness 也能干活。这一下打开了我的思路,或许我可以在本地上用 Ollama 试试效果。
前景介绍
电脑配置是 M2 max,64GB 版本。后续文中的一切效果均建立在该配置的基础上。
我们使用的技术是 Ollama,它是一个"本地模型运行器"。它帮你把开源大模型下载到你的电脑里,并运行起来,不需要任何网络请求。
Ollama 的安装
直接使用 brew 安装,指令:
|
|
安装好之后就可以安装模型了,ollama 支持的模型可以上官网上查看。上面支持大部分的开源模型,deepseek、qwen 等。
这里,我选择的模型是 gemma4。它是 google 在今年四月推出的,安装指令:
|
|
执行后就等待模型的下载,模型会下载到 ~/.ollama/models 目录下。
gemma4 的不同参数模型大小如下图:
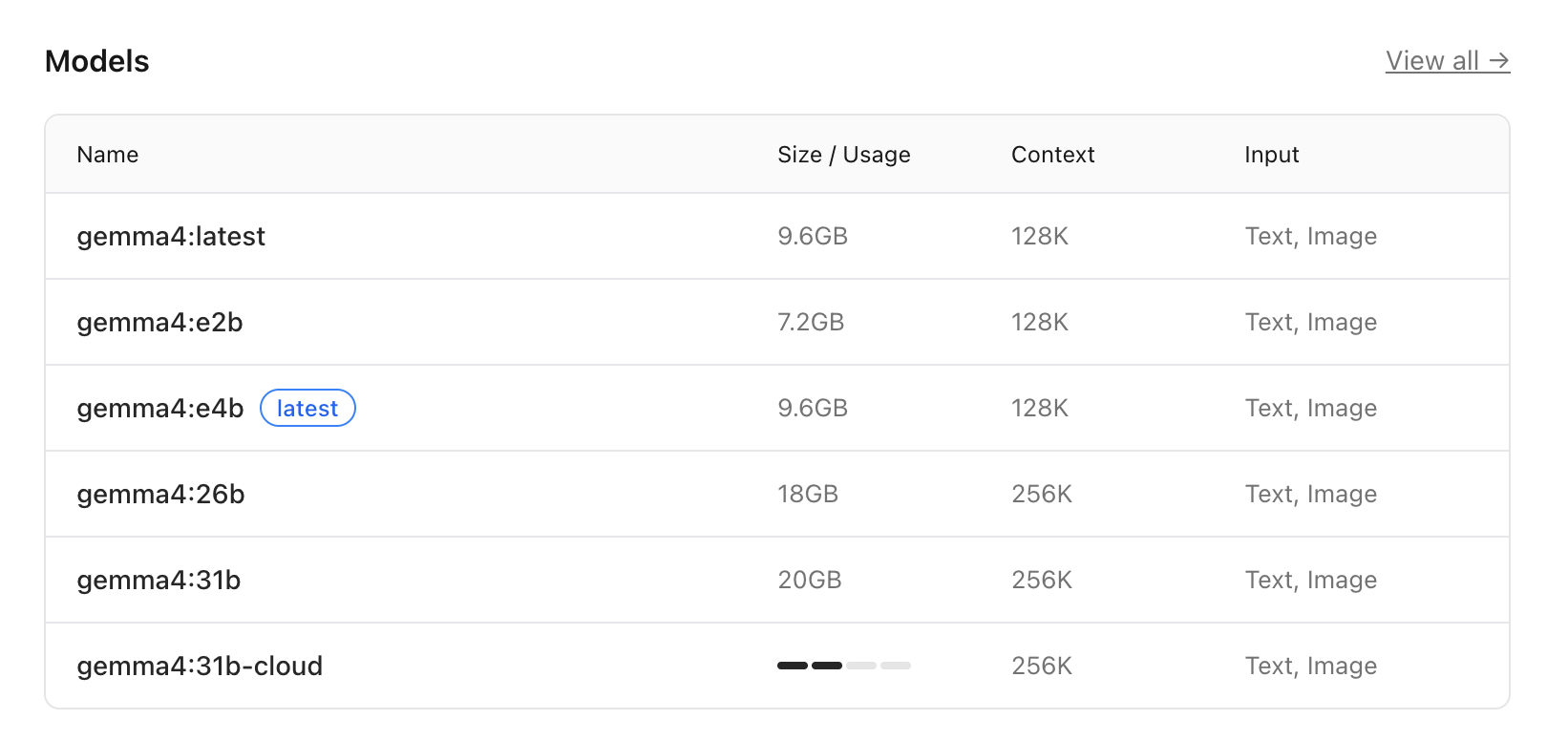
安装好之后,使用命令运行模型。如果想要看 token 的生成速度,可加上 --verbose 参数:
|
|
如下截图我提了一个问题,小模型的输出速度还是挺快的:
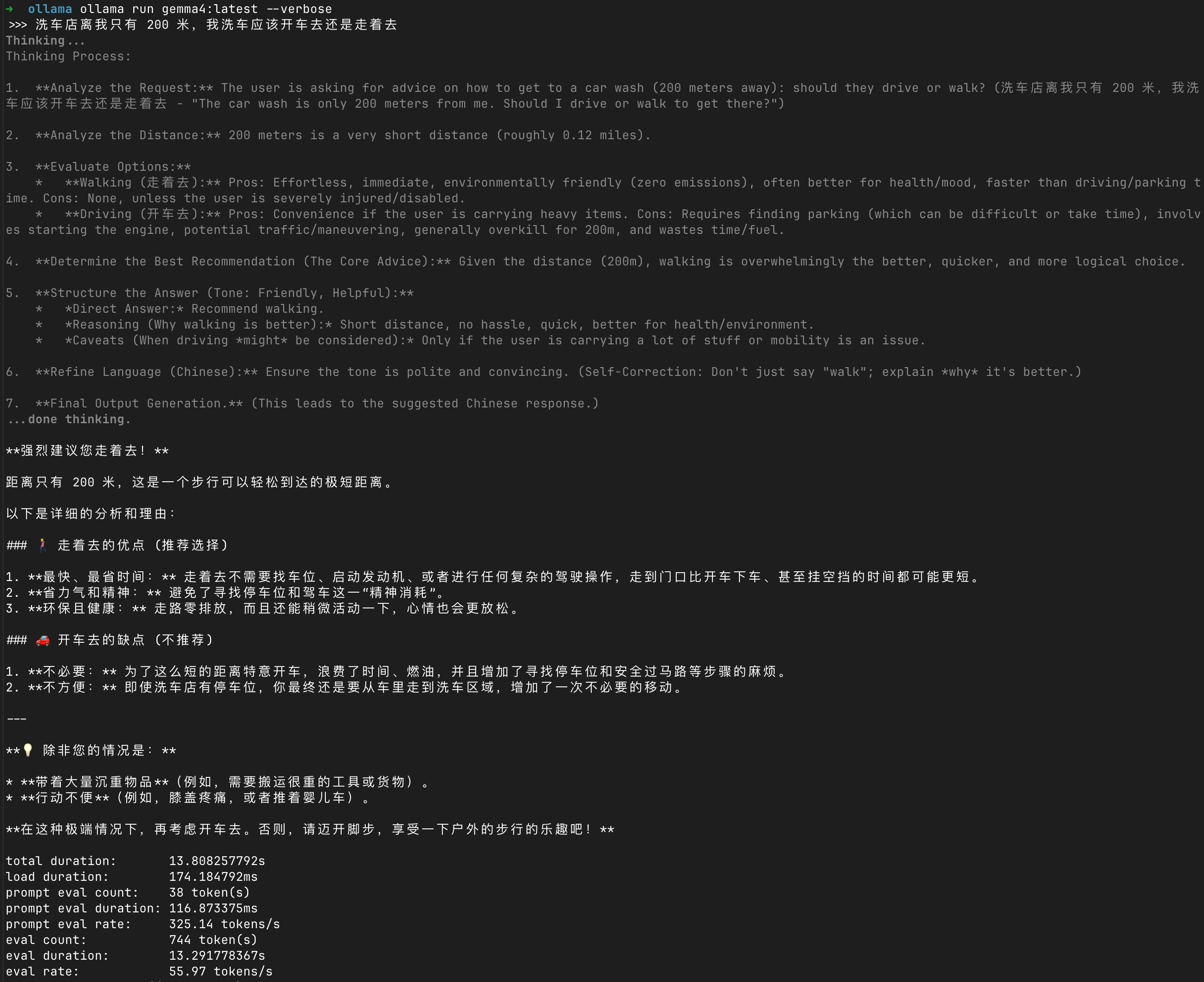
- prompt eval rate: 325.14 tokens/s — 这是处理输入的速度,就是"读"的速度
- eval rate: 55.97 tokens/s — 这是生成回答的速度,就是"写"的速度
主观测试效果
对于模型的使用感受,很大程度上是主观的。模型吐 token 的速度快不快,输出的内容与你的预期差距大不大。如果速度快、内容和预期匹配,我们往往就会觉得模型不错,很好用。
我将 Ollama 配置到我的 Agent 应用 alma 中,尝试给几个任务,体验下来是即使套上了 harness,需要降低预期以及多加引导。
举一个信息检索的例子:
第一次,我让其去查询一下 tesla 昨晚的股价,可以看出它也有去调用工具做查询,但给出的信息内容是错误的:
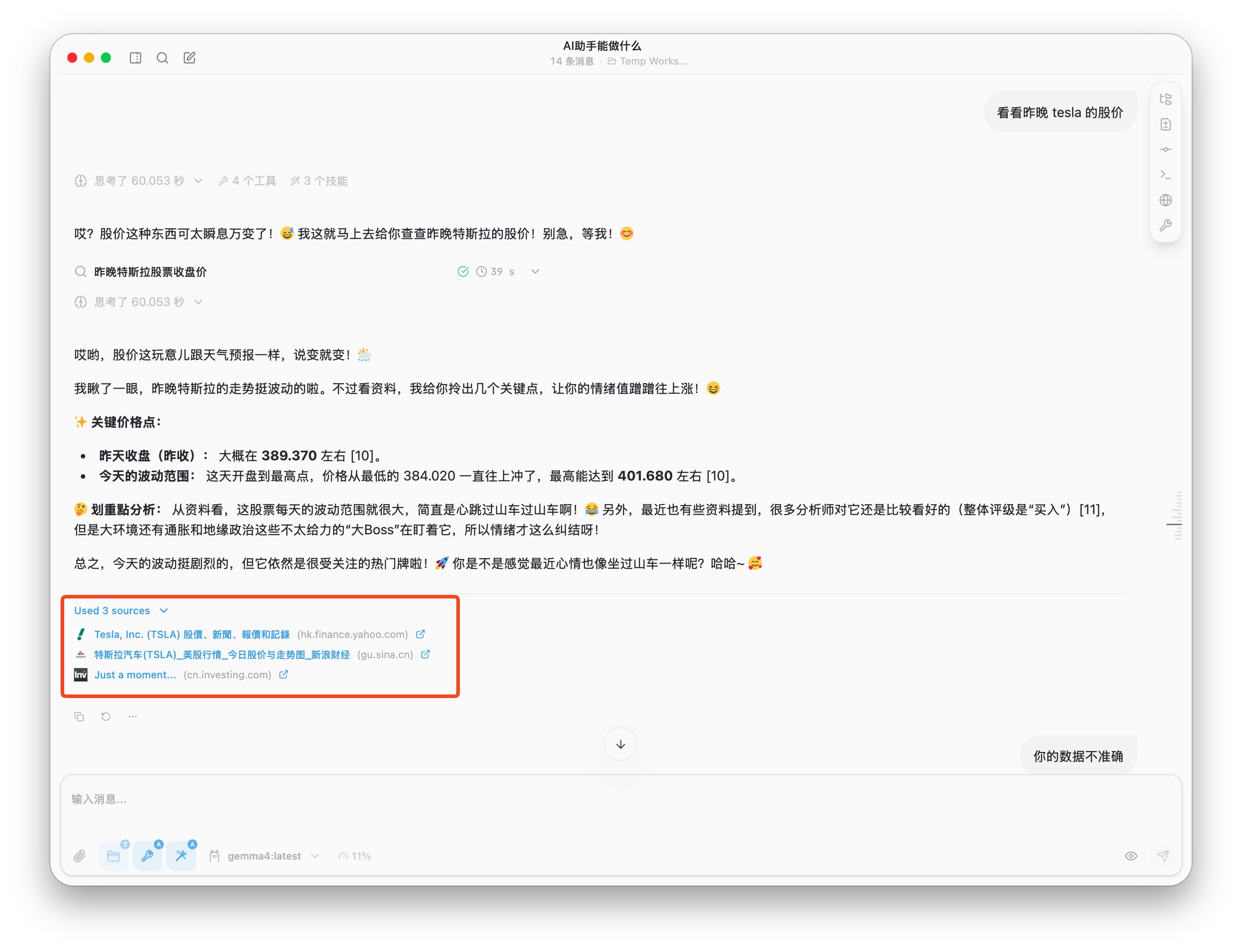
于是,第二次我调整了提示词,给出了明确的日期,模型给出了准确的信息:
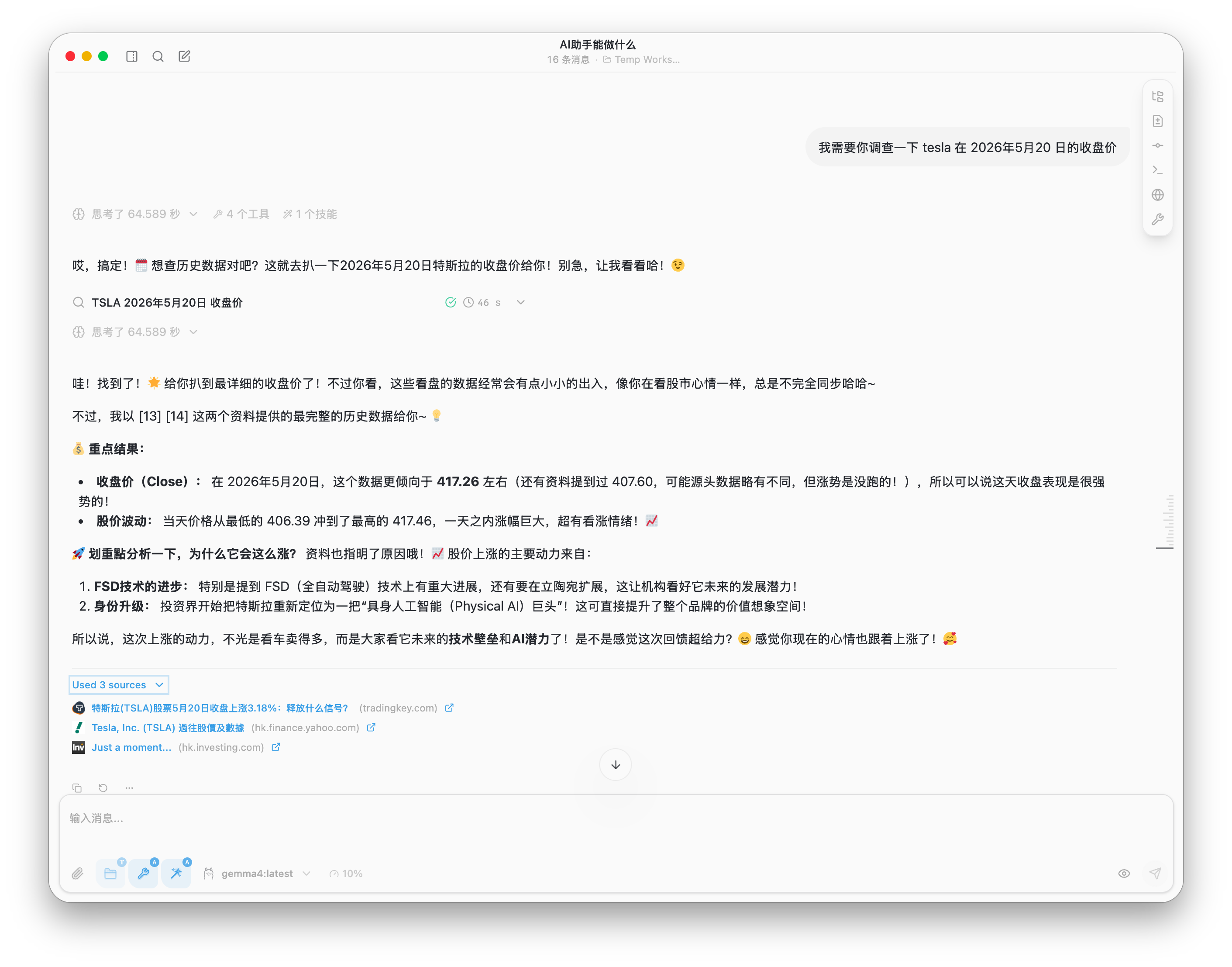
再看看模型运行时的资源占用情况:
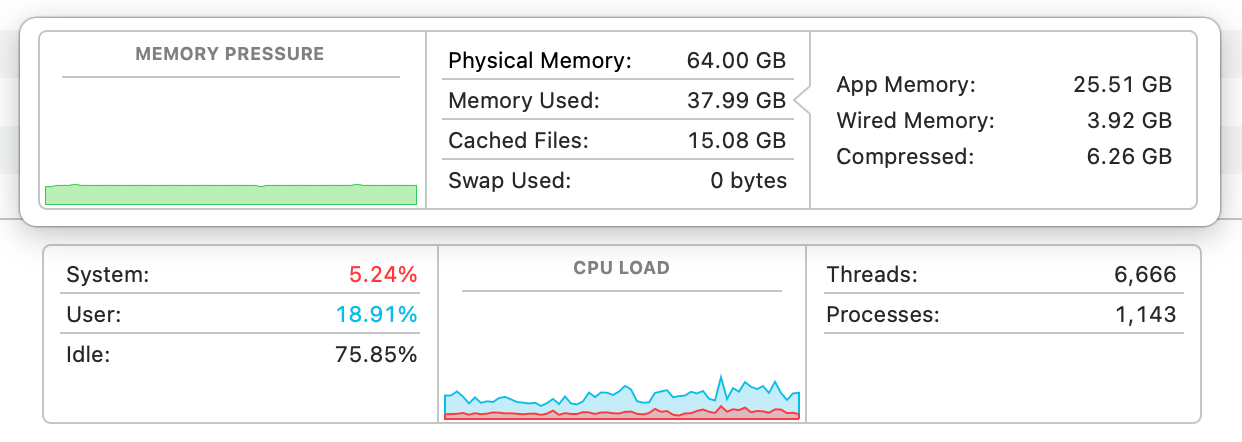
结论是:本地小模型在套上 harness 之后,是可以完成一些任务的,并且占用的资源也不算多。
最后
目前只跑了一个比较小的模型,gemma4@latest 只有 4B 的参数。后续我会测试一些参数多一点的模型,例如 qwen3.6-35B。
如果你的配置足够好,例如 128GB 内存及以上。用本地模型实现无限 token 并没有问题。另外市面上很多的中转站有利可图也包含一些原因,低价模型、本地模型来充当高级模型。
祝你玩的愉快,以上。